1. Logging in EKS
- Amazon Elastic Kubernetes Service (EKS)에서 로깅은 클러스터의 작업 및 이벤트에 대한 정보를 기록하고 분석하는 프로세스입니다. 이를 통해 애플리케이션 및 인프라의 상태를 모니터링하고, 문제를 식별하고, 보안 및 운영 요구 사항을 충족시키는 데 도움이 됩니다. EKS에서는 주로 다음과 같은 로깅 옵션을 사용합니다.
- Amazon CloudWatch Logs
- EKS 클러스터의 로그를 Amazon CloudWatch Logs로 전송하여 저장할 수 있습니다.
- 로그 그룹을 생성하고, 로그 스트림에 로그를 전송하여 모니터링 및 분석합니다.
- Kubernetes API 서버, 컨트롤 플레인 구성 요소, 워커 노드의 애플리케이션 로그 등을 수집할 수 있습니다.
- Amazon CloudWatch Container Insights
- Amazon CloudWatch Container Insights를 사용하면 EKS 클러스터의 컨테이너화된 애플리케이션 로그 및 메트릭을 수집하고 모니터링할 수 있습니다.
- Prometheus 및 Fluentd 메트릭을 통합하여 클러스터 및 애플리케이션의 상태를 시각화할 수 있습니다.
- Amazon Managed Service for Prometheus
- Amazon Managed Service for Prometheus (AMP)를 사용하여 Prometheus 서버를 프로비저닝하고 데이터를 수집할 수 있습니다.
- AMP는 Kubernetes 클러스터에서 Prometheus 메트릭을 수집하고 저장하는 데 사용될 수 있습니다.
- Third-Party Logging Solutions
- EKS 클러스터에서는 다양한 서드파티 로깅 솔루션을 사용할 수도 있습니다. Fluentd, Logstash, Elasticsearch와 같은 도구를 사용하여 로그를 수집하고 처리할 수 있습니다.
- 하기 테스트는 Amazon CloudWatch Logs 로 진행합니다.
1-1) EKS Logging 설정 (Amazon CloudWatch Logs)
- EKS 는 옵션을 설정하여 로그를 남길수 있으며 디폴트 설정이 로깅 비활성화로 되어있으므로 활성화해줘야합니다.
- 수집된 컨트롤 플레인 로그는 Cloudwatch에서 확인 가능합니다. (참고 URL)https://malwareanalysis.tistory.com/600
EKS 스터디 - 4주차 1편 - 컨트롤 플레인 로깅
안녕하세요. 이 글은 EKS 컨트롤 플레인 로그수집 방법을 설명합니다. EKS 컨트롤 플레인 로그란? 컨트롤 플레인 발생한 이벤트를 EKS 옵션을 설정하여 로그로 남길 수 있습니다. 디폴트 설정은 로
malwareanalysis.tistory.com
- 수집된 컨트롤 플레인 로그는 CloudWatch의 로그그룹을 통해 확인 가능합니다.
- "api","audit","authenticator","controllerManager","scheduler" type에대한 로깅 활성화
AWS_DEFAULT_REGION=ap-northeast-2
CLUSTER_NAME=junho-test-eks
# 모든 로깅 활성화
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
# 로그 그룹 확인
aws logs describe-log-groups | jq
1-2) EKS Log 확인 (w. CloudWatch Log Insights)
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
- Amazon CloudWatch Logs Insights는 Amazon CloudWatch Logs의 기능 중 하나로, 로그 데이터를 쿼리하고 분석하는 서비스입니다. 이를 통해 대규모 로그 데이터를 실시간으로 탐색하고 분석하여 유용한 정보를 추출할 수 있습니다. CloudWatch Logs Insights는 다음과 같은 기능과 장점을 제공합니다.
- 실시간 검색 및 필터링: CloudWatch Logs Insights를 사용하면 로그 데이터를 실시간으로 검색하고 원하는 필드 또는 키워드를 기반으로 데이터를 필터링할 수 있습니다. 이를 통해 특정 이벤트나 패턴을 쉽게 발견할 수 있습니다.
- 집계 및 통계: 쿼리를 사용하여 로그 데이터를 집계하고 통계 정보를 생성할 수 있습니다. 예를 들어, 로그에서 특정 시간 범위의 요청 수, 평균 응답 시간 등을 계산하여 성능 및 사용량에 대한 인사이트를 얻을 수 있습니다.
- 시각화: 쿼리 결과를 시각화하여 대시보드에 표시할 수 있습니다. CloudWatch Logs Insights는 간단한 차트와 그래프를 생성하여 데이터를 빠르게 이해하고 시각적으로 표현할 수 있도록 지원합니다.
- 다양한 데이터 포맷 지원: CloudWatch Logs Insights는 다양한 로그 데이터 형식을 지원합니다. JSON, CSV, 공백으로 구분된 데이터 등 다양한 형식의 로그를 처리할 수 있습니다.
- 사용자 정의 쿼리: CloudWatch Logs Insights는 강력한 쿼리 언어를 제공하여 복잡한 질의를 작성할 수 있습니다. 필드 추출, 조인, 필터링, 정렬 등 다양한 기능을 활용하여 데이터를 분석할 수 있습니다.
- EC2 Instance가 NodeNotReady 상태인 로그 검색
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
- kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
- CloudWatch Log Insight Query with AWS CLI
# CloudWatch Log Insight Query
aws logs get-query-results --query-id $(aws logs start-query \
--log-group-name '/aws/eks/junho-test-eks/cluster' \
--start-time `date -d "-1 hours" +%s` \
--end-time `date +%s` \
--query-string 'fields @timestamp, @message | filter @logStream ~= "kube-scheduler" | sort @timestamp desc' \
| jq --raw-output '.queryId')
- 로깅 끄기
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
- 컨테이너(파드) 로깅
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 개인 도메인 인증서 ARN 확인
MyDomain=junholee.site
CERT_ARN=$(aws acm list-certificates --query "CertificateSummaryList[?DomainName=='${MyDomain}'].CertificateArn" --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# LB Subnet ID
subnet1=subnet-055c4f6c17789c2bc
subnet2=subnet-098f87dfe44cefca7
subnet3=subnet-05c08334955a4d68e
# 파라미터 파일 생성 : 인증서 ARN 지정하지 않아도 가능! 혹시 https 리스너 설정 안 될 경우 인증서 설정 추가(주석 제거)해서 배포 할 것
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/subnets: $subnet1, $subnet2, $subnet3
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
#alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
external-dns.alpha.kubernetes.io/hostname: nginx.$MyDomain
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 15.14.0 -f nginx-values.yaml
# 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f


- 컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고합니다.
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이, 애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능합니다.
# 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
2. Prometheus
- Prometheus는 오픈소스 시스템 모니터링 및 경고 솔루션으로, 클라우드 환경과 온프레미스 환경에서 널리 사용되고 있는 프로젝트입니다. Prometheus는 쉽게 설정할 수 있는 플러그인 아키텍처와 강력한 쿼리 언어를 통해 다양한 메트릭을 수집하고 분석할 수 있습니다. 이를 통해 시스템 및 서비스의 상태를 실시간으로 모니터링하고 관리할 수 있습니다.
- 주요 구성 요소
- Prometheus Server: 메트릭 데이터를 수집하고 저장하는 핵심 컴포넌트입니다. 주기적으로 설정된 엔드포인트로부터 메트릭을 스크랩하여 저장하고, 쿼리 언어를 사용하여 데이터를 조회할 수 있습니다.
- Prometheus Exporters: 서비스, 애플리케이션 또는 시스템에서 메트릭을 수집하여 Prometheus 서버로 보내는 역할을 합니다. 예를 들어, Node Exporter는 호스트 시스템의 메트릭을 수집하고, Blackbox Exporter는 외부 서비스의 가용성을 모니터링합니다.
- Prometheus Alertmanager: 경고 및 알림 관리를 담당하는 컴포넌트입니다. Prometheus 서버에서 발생한 경고를 수신하고, 정의된 규칙에 따라 알림을 생성하거나 다양한 알림 채널로 전달합니다.
- Grafana: Prometheus와 연동하여 메트릭 데이터를 시각화하는 대시보드 도구입니다. Grafana를 사용하면 다양한 차트, 그래프, 테이블 등을 생성하여 메트릭 데이터를 시각적으로 분석하고 모니터링할 수 있습니다.
- 주요 기능
- 다양한 데이터 수집: Prometheus는 다양한 데이터 소스에서 메트릭을 수집할 수 있는 다양한 Exporter를 제공합니다. 이를 통해 서버, 애플리케이션, 네트워크 등의 다양한 환경에서 메트릭을 수집할 수 있습니다.
- 시계열 데이터베이스: Prometheus는 내부적으로 시계열 데이터베이스를 사용하여 메트릭을 저장하고 쿼리합니다. 이를 통해 고성능의 시계열 데이터 처리와 저장을 지원합니다.
- 유연한 쿼리 언어: PromQL이라는 강력한 쿼리 언어를 제공하여 메트릭 데이터를 다양한 방법으로 쿼리하고 분석할 수 있습니다. 집계, 필터링, 그룹화 등 다양한 기능을 활용할 수 있습니다.
- 스크래핑 및 수집 주기 설정: Prometheus는 정기적으로 데이터를 수집하기 위한 스크랩 및 수집 주기 설정을 제공합니다. 이를 통해 메트릭 데이터를 주기적으로 업데이트하고 모니터링할 수 있습니다.
- 경고 및 알림 관리: Prometheus Alertmanager를 통해 정의된 경고 규칙에 따라 경고를 생성하고 관리할 수 있습니다. 이를 통해 시스템의 이상 상태를 신속하게 감지하고 대응할 수 있습니다.
- 커뮤니티와 확장성: Prometheus는 활발한 커뮤니티와 다양한 플러그인, 인티그레이션을 지원하여 확장성과 유연성을 제공합니다. 사용자는 자신의 환경에 맞게 Prometheus를 확장하고 사용할 수 있습니다.
2-1) 프로메테우스-스택 설치
- 프로메테우스-스택 설치 : 모니터링에 필요한 여러 요소를 단일 차트(스택)으로 제공 ← 시각화(그라파나), 이벤트 메시지 정책(경고 임계값, 경고 수준) 등
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 개인 도메인 인증서 ARN 확인
MyDomain=junholee.site
CERT_ARN=$(aws acm list-certificates --query "CertificateSummaryList[?DomainName=='${MyDomain}'].CertificateArn" --output text)
echo $CERT_ARN
# LB Subnet ID
subnet1=subnet-055c4f6c17789c2bc
subnet2=subnet-098f87dfe44cefca7
subnet3=subnet-05c08334955a4d68e
# repo 추가
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > monitor-values.yaml
prometheus:
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: gp3
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 30Gi
ingress:
enabled: true
ingressClassName: alb
hosts:
- prometheus.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/subnets: $subnet1, $subnet2, $subnet3
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
external-dns.alpha.kubernetes.io/hostname: prometheus.$MyDomain
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
hosts:
- grafana.$MyDomain
paths:
- /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/subnets: $subnet1, $subnet2, $subnet3
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: myeks-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
external-dns.alpha.kubernetes.io/hostname: grafana.$MyDomain
persistence:
enabled: true
type: sts
storageClassName: "gp3"
accessModes:
- ReadWriteOnce
size: 20Gi
defaultRules:
create: false
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
alertmanager:
enabled: false
EOT
cat monitor-values.yaml | yh
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 57.1.0 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
helm list -n monitoring
kubectl get pod,svc,ingress,pvc -n monitoring

2-2) AWS CNI Metrics 수집
- AWS CNI Metrics 수집을 위한 사전 설정은 다음과 같습니다.
# PodMonitor 배포
cat <<EOF | kubectl create -f -
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
EOF
# PodMonitor 확인
kubectl get podmonitor -n kube-system
kubectl get podmonitor -n kube-system aws-cni-metrics -o yaml | kubectl neat | yh
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: aws-cni-metrics
namespace: kube-system
spec:
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
podMetricsEndpoints:
- interval: 30s
path: /metrics
port: metrics
selector:
matchLabels:
k8s-app: aws-node
- 프로메테우스 Target , job (aws-cni 검색)을 확인합니다.

2-3) 프로메테우스 사용법
- 프로메테우스 기본 사용 : 모니터링 그래프
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출됩니다.
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장됩니다.
- 웹 상단 주요 메뉴 설명
- 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
- 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
- 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
- 도움말(Help)

- 쿼리 입력 옵션
- Use local time : 출력 시간을 로컬 타임으로 변경
- Enable query history : PromQL 쿼리 히스토리 활성화
- Enable autocomplete : 자동 완성 기능 활성화
- Enable highlighting : 하이라이팅 기능 활성화
- Enable linter : ?
- 프로메테우스 설정(Configuration) 확인 : Status → Runtime & Build Information 클릭
- Storage retention : 5d or 10GiB → 메트릭 저장 기간이 5일 경과 혹은 10GiB 이상 시 오래된 것부터 삭제 ⇒ helm 파라미터에서 수정 가능
- 프로메테우스 설정(Configuration) 확인 : Status → Command-Line Flags 클릭
- -log.level : info
- -storage.tsdb.retention.size : 10GiB
- -storage.tsdb.retention.time : 5d
- 프로메테우스 설정(Configuration) 확인 : Status → Configuration ⇒ “node-exporter” 검색
- job name 을 기준으로 scraping
global:
scrape_interval: 15s # 메트릭 가져오는(scrape) 주기
scrape_timeout: 10s # 메트릭 가져오는(scrape) 타임아웃
evaluation_interval: 15s # alert 보낼지 말지 판단하는 주기
...
- job_name: serviceMonitor/monitoring/kube-prometheus-stack-prometheus-node-exporter/0
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
...
kubernetes_sd_configs: # 서비스 디스커버리(SD) 방식을 이용하고, 파드의 엔드포인트 List 자동 반영
- role: endpoints
kubeconfig_file: ""
follow_redirects: true
enable_http2: true
namespaces:
own_namespace: false
names:
- monitoring # 서비스 엔드포인트가 속한 네임 스페이스 이름을 지정, 서비스 네임스페이스가 속한 포트 번호를 구분하여 메트릭 정보를 가져옴
- 전체 메트릭 대상(Targets) 확인 : Status → Targets
- 해당 스택은 ‘노드-익스포터’, cAdvisor, 쿠버네티스 전반적인 현황 이외에 다양한 메트릭을 포함됩니다.
- 프로메테우스 설정(Configuration) 확인 : Status → Service Discovery : 모든 endpoint 로 도달 가능 시 자동 발견!, 도달 규칙은 설정Configuration 파일에 정의합니다.
- 예) serviceMonitor/monitoring/kube-prometheus-stack-apiserver/0 경우 해당 address="192.168.1.53:443" 도달 가능 시 자동 발견됩니다.
- 메트릭을 그래프(Graph)로 조회 : Graph - 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 → Graph 확인
- 혹은 지구 아이콘(Metrics Explorer) 클릭 시 전체 메트릭 출력되며, 해당 메트릭 클릭해서 확인합니다.

2-4) [중급] 쿼리 : node-exporter , kube-state-metrics , kube-proxy
- 쿼리 : node-exporter
# Table 아래 쿼리 입력 후 Execute 클릭 -> Graph 확인
## 출력되는 메트릭 정보는 node-exporter 를 통해서 노드에서 수집된 정보
node_memory_Active_bytes
# 특정 노드(인스턴스) 필터링 : 아래 IP는 출력되는 자신의 인스턴스 PrivateIP 입력 후 Execute 클릭 -> Graph 확인
node_memory_Active_bytes{instance="10.143.7.183:9100"}
- 쿼리 : kube-state-metrics
# replicas's number
kube_deployment_status_replicas
kube_deployment_status_replicas_available
kube_deployment_status_replicas_available{deployment="coredns"}
# scale out
kubectl scale deployment -n kube-system coredns --replicas 3
# 확인
kube_deployment_status_replicas_available{deployment="coredns"}


- 쿼리 : kube-proxy
kubeproxy_sync_proxy_rules_iptables_total
kubeproxy_sync_proxy_rules_iptables_total{table="filter"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat"}
kubeproxy_sync_proxy_rules_iptables_total{table="nat", instance="10.143.7.183:10249"}
2-5) [중급] 쿼리 : 애플리케이션 - NGINX 웹서버 애플리케이션 모니터링 설정 및 접속
- nginx 를 helm 설치 시 프로메테우스 익스포터 Exporter 옵션 설정 시 자동으로 nginx 를 프로메테우스 모니터링에 등록 가능합니다.
- 프로메테우스 설정에서 nginx 모니터링 관련 내용을 서비스 모니터 CRD로 추가 가능!
- 기존 애플리케이션 파드에 프로메테우스 모니터링을 추가하려면 사이드카 방식을 사용하며 exporter 컨테이너를 추가!
- nginx 웹 서버(with helm)에 metrics 수집 설정 추가
# 모니터링
watch -d "kubectl get pod; echo; kubectl get servicemonitors -n monitoring"
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용
cat <<EOT > ~/nginx_metric-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm upgrade nginx bitnami/nginx --reuse-values -f nginx_metric-values.yaml
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# 메트릭 확인 >> 프로메테우스에서 Target 확인
NGINXIP=$(kubectl get pod -l app.kubernetes.io/instance=nginx -o jsonpath={.items[0].status.podIP})
curl -s http://$NGINXIP:9113/metrics # nginx_connections_active Y 값 확인해보기
curl -s http://$NGINXIP:9113/metrics | grep ^nginx_connections_active
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
- 서비스 모니터링 생성 후 3분 정도 후에 프로메테우스 웹서버에서 State → Targets 에 nginx 서비스 모니터 추가 확인합니다.

- State → Configuration : nginx 검색 후 job을 확인합니다.

- 설정이 자동으로 반영되는 원리는 주요 config 적용 필요 시 reloader 동작하는 방식입니다.
kubectl describe pod -n monitoring prometheus-kube-prometheus-stack-prometheus-0
- 쿼리 : 애플리케이션, Graph → nginx_ 입력 시 다양한 메트릭 추가 확인 : nginx_connections_active 등
# nginx scale out : Targets 확인
kubectl scale deployment nginx --replicas 2
# 쿼리 Table -> Graph
nginx_up
nginx_http_requests_total
nginx_connections_active


2-5) [중급] PromQL
- 프로메테우스 메트릭 종류 (4종) : Counter, Gauge, Histogram, Summary - Link Blog
- 게이지 Gauge : 특정 시점의 값을 표현하기 위해서 사용하는 메트릭 타입, CPU 온도나 메모리 사용량에 대한 현재 시점 값
- 카운터 Counter : 누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간 별로 변화(추세) 확인, 계속 증가 → 함수 등으로 활용
- 서머리 Summary : 구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
- 히스토그램 Histogram : 사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도를 측정 → 함수로 측정 포맷을 변경
- PromQL Query - Docs Operator Example
- Label Matchers : = , ! = , =~ 정규표현식
# 예시
node_memory_Active_bytes
node_memory_Active_bytes{instance="192.168.1.188:9100"}
node_memory_Active_bytes{instance!="192.168.1.188:9100"}
# 정규표현식
node_memory_Active_bytes{instance=~"192.168.+"}
node_memory_Active_bytes{instance=~"192.168.1.+"}
# 다수 대상
node_memory_Active_bytes{instance=~"192.168.1.188:9100|192.168.2.170:9100"}
node_memory_Active_bytes{instance!~"192.168.1.188:9100|192.168.2.170:9100"}
# 여러 조건 AND
kube_deployment_status_replicas_available{namespace="kube-system"}
kube_deployment_status_replicas_available{namespace="kube-system", deployment="coredns"}
- Binary Operators 이진 연산자 - Link
- 산술 이진 연산자 : + - * / * ^
- 비교 이진 연산자 : = = ! = > < > = < =
- 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
# 산술 이진 연산자 : + - * / * ^
node_memory_Active_bytes
node_memory_Active_bytes/1024
node_memory_Active_bytes/1024/1024
# 비교 이진 연산자 : = = ! = > < > = < =
nginx_http_requests_total
nginx_http_requests_total > 100
nginx_http_requests_total > 10000
# 논리/집합 이진 연산자 : and 교집합 , or 합집합 , unless 차집합
kube_pod_status_ready
kube_pod_container_resource_requests
kube_pod_status_ready == 1
kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 or kube_pod_container_resource_requests > 1
kube_pod_status_ready == 1 and kube_pod_container_resource_requests > 1
- Aggregation Operators 집계 연산자 - Link
- sum (calculate sum over dimensions) : 조회된 값들을 모두 더함
- min (select minimum over dimensions) : 조회된 값에서 가장 작은 값을 선택
- max (select maximum over dimensions) : 조회된 값에서 가장 큰 값을 선택
- avg (calculate the average over dimensions) : 조회된 값들의 평균 값을 계산
- group (all values in the resulting vector are 1) : 조회된 값을 모두 ‘1’로 바꿔서 출력
- stddev (calculate population standard deviation over dimensions) : 조회된 값들의 모 표준 편차를 계산
- stdvar (calculate population standard variance over dimensions) : 조회된 값들의 모 표준 분산을 계산
- count (count number of elements in the vector) : 조회된 값들의 갯수를 출력 / 인스턴스 벡터에서만 사용 가능
- count_values (count number of elements with the same value) : 같은 값을 가지는 요소의 갯수를 출력
- bottomk (smallest k elements by sample value) : 조회된 값들 중에 가장 작은 값들 k 개 출력
- topk (largest k elements by sample value) : 조회된 값들 중에 가장 큰 값들 k 개 출력
- quantile (calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions) : 조회된 값들을 사분위로 나눠서 (0 < $ < 1)로 구성하고, $에 해당 하는 요소들을 출력
#
node_memory_Active_bytes
# 출력 값 중 Top 3
topk(3, node_memory_Active_bytes)
# 출력 값 중 하위 3
bottomk(3, node_memory_Active_bytes)
bottomk(3, node_memory_Active_bytes>0)
# node 그룹별: by
node_cpu_seconds_total
node_cpu_seconds_total{mode="user"}
node_cpu_seconds_total{mode="system"}
avg(node_cpu_seconds_total)
avg(node_cpu_seconds_total) by (instance)
avg(node_cpu_seconds_total{mode="user"}) by (instance)
avg(node_cpu_seconds_total{mode="system"}) by (instance)
#
nginx_http_requests_total
sum(nginx_http_requests_total)
sum(nginx_http_requests_total) by (instance)
# 특정 내용 제외하고 출력 : without
nginx_http_requests_total
sum(nginx_http_requests_total) without (instance)
sum(nginx_http_requests_total) without (instance,container,endpoint,job,namespace)


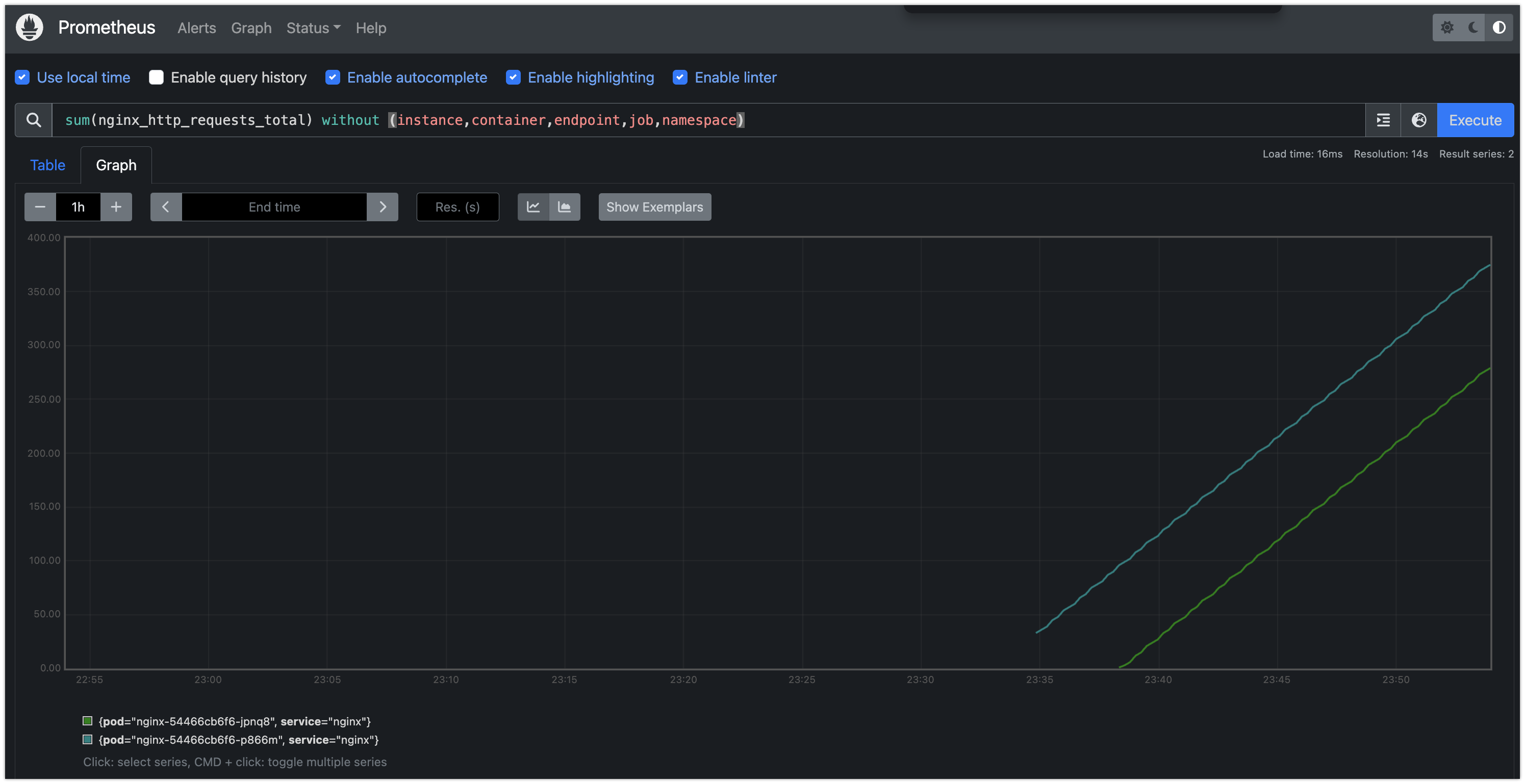
- Time series selectors : Instant/Range vector selectors, Time Durations, Offset modifier, @ modifier - Link
- 인스턴스 벡터 Instant Vector : 시점에 대한 메트릭 값만을 가지는 데이터 타입
- 레인지 벡터 Range Vector : 시간의 구간을 가지는 데이터 타입
- 시간 단위 : ms, s, m(주로 분 사용), h, d, w, y
# 시점 데이터
node_cpu_seconds_total
# 15초 마다 수집하니 아래는 지난 4회차/8회차의 값 출력
node_cpu_seconds_total[1m]
node_cpu_seconds_total[2m]
# 서비스 정보 >> 네임스페이스별 >> cluster_ip 별
kube_service_info
count(kube_service_info)
count(kube_service_info) by (namespace)
count(kube_service_info) by (cluster_ip)

# 컨테이너가 사용 메모리 -> 파드별
container_memory_working_set_bytes
sum(container_memory_working_set_bytes)
sum(container_memory_working_set_bytes) by (pod)
topk(5,sum(container_memory_working_set_bytes) by (pod))
topk(5,sum(container_memory_working_set_bytes) by (pod))/1024/1024

3. Grafana
소개 및 웹 접속 : TSDB 데이터를 시각화, 다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
- 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음 → 현재 실습 환경에서는 데이터 소스는 프로메테우스를 사용
# 그라파나 버전 확인
kubectl exec -it -n monitoring deploy/kube-prometheus-stack-grafana -- grafana-cli --version
grafana cli version 10.4.0
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속 : 기본 계정 - admin / prom-operator
echo -e "Grafana Web URL = https://grafana.$MyDomain"
우측 상단 : admin 사용자의 개인 설정
기본 대시보드 확인

- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Connections : 설정, 예) 데이터 소스 설정 등
- Administartor : 사용자, 조직, 플러그인 등 설정
Connections → Your connections : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠 ← 서비스 주소 확인

대시보드 사용 : 기본 대시보드와 공식 대시보드 가져오기
기본 대시보드
- 스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
- (대략) 분류 : 자원 사용량 - Cluster/POD Resources, 노드 자원 사용량 - Node Exporter, 주요 애플리케이션 - CoreDNS 등
- 확인해보자 - K8S / CR / Cluster, Node Exporter / Use Method / Cluster


- [Kubernetes / Views / Global] Dashboard → New → Import → 15757 력입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭


- [1 Kubernetes All-in-one Cluster Monitoring KR] Dashboard → New → Import → 17900 입력 후 Load ⇒ 데이터소스(Prometheus 선택) 후 Import 클릭

해당 패널에서 Edit → 아래 수정 쿼리 입력 후 Run queries 클릭 → 상단 Save 후 Apply
# CPU 기본 설정
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))
# CPU 설정 수정
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))
# 메모리 점유율 기본 설정
(node_memory_MemTotal_bytes{node="$node"}-node_memory_MemAvailable_bytes{node="$node"})/node_memory_MemTotal_bytes{node="$node"}
# 메모리 점유율 수정
(node_memory_MemTotal_bytes{instance="$instance"}-node_memory_MemAvailable_bytes{instance="$instance"})/node_memory_MemTotal_bytes{instance="$instance"}
# 디스크 사용율 기본 설정
sum(node_filesystem_size_bytes{node="$node"} - node_filesystem_avail_bytes{node="$node"}) by (node) / sum(node_filesystem_size_bytes{node="$node"}) by (node)
# 디스크 사용율 수정
sum(node_filesystem_size_bytes{instance="$instance"} - node_filesystem_avail_bytes{instance="$instance"}) by (node) / sum(node_filesystem_size_bytes{instance="$instance"}) by (node)
NGINX 애플리케이션 모니터링 대시보드 추가
그라파나에 12708 대시보드 추가

- [중급] Panel 패널 - Link
- 실습 준비 : 신규 대시보스 생성 → 패널 생성(Code 로 변경) → 쿼리 입력 후 Run queries 클릭 후 오른쪽 상단 Apply 클릭 → 대시보드 상단 저장
1. Time series : 아래 쿼리 입력 후 오른쪽 입력 → Title(노드별 5분간 CPU 사용 변화율)
node_cpu_seconds_total
rate(node_cpu_seconds_total[5m])
sum(rate(node_cpu_seconds_total[5m]))
sum(rate(node_cpu_seconds_total[5m])) by (instance)
2. Bar chart : Add → Visualization 오른쪽(Bar chart) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(네임스페이스 별 디플로이먼트 갯수)
kube_deployment_status_replicas_available
count(kube_deployment_status_replicas_available) by (namespace)

3. Stat : Add → Visualization 오른쪽(Stat) → Title(nginx 파드 수)
kube_deployment_spec_replicas
kube_deployment_spec_replicas{deployment="nginx"}
# scale out
kubectl scale deployment nginx --replicas 6
4. Gauge : Add → Visualization 오른쪽(Gauge) → Title(노드 별 1분간 CPU 사용률)
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}[1m]
node_cpu_seconds_total
node_cpu_seconds_total{mode="idle"}
node_cpu_seconds_total{mode="idle"}[1m]
rate(node_cpu_seconds_total{mode="idle"}[1m])
avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))
5. Table : Add → Visualization 오른쪽(Table) ⇒ 쿼리 Options : Format(Table), Type(Instance) → Title(노드 OS 정보)
node_os_info

'EKS' 카테고리의 다른 글
| [EKS] Security (0) | 2024.04.14 |
|---|---|
| [EKS] Autoscaling (0) | 2024.04.06 |
| [EKS] AWS EKS의 Storage & Nodegroup (1) | 2024.03.23 |
| [EKS] AWS EKS의 Networking (VPC CNI, LB Controller) (0) | 2024.03.16 |
| [EKS] AWS EKS의 특징과 Cluster Endpoint 통신 방식 (0) | 2024.03.09 |



