728x90
반응형
1. Kafka 란?
- 대용량의 데이터 스트림을 처리하는 분산형 스트리밍
- 기능
- 매우 높은 처리량과 짧은 대기 시간으로 데이터를 공유하는 마이크로서비스 및 기타 애플리케이션
- 메시지 순서 보장
- 애플리케이션 상태를 재구성하기 위해 데이터 저장소에서 메시지 되감기/재생
- 키-값 로그를 사용할 때 오래된 레코드를 제거하기 위한 메시지 압축
- 클러스터 구성의 수평적 확장성
- 내결함성을 제어하기 위한 데이터 복제
- 즉각적인 액세스를 위해 대용량 데이터 보존
- 스트림 데이터
- Kafka는 스트림 데이터 처리에 강점을 가지고 있음
- 스트림 데이터는 데이터의 연속적인 흐름을 말하며, 이는 실시간으로 발생하거나 쌓여가는 데이터를 의미
- 기존 데이터와의 차이는 주로 데이터의 처리 방식에 있으며 스트림 데이터는 순차적으로 처리
- 카프카 주요 요소
- 주키퍼 ZooKeeper : 카프카의 메타데이터 관리 및 브로커의 정상 상태 점검 health check 을 담당
- IMPORTANT : KRaft mode is not ready for production in Apache Kafka or in Strimzi - Link
- 카프카 Kafka 또는 카프카 클러스터 Kafka cluster : 여러 대의 브로커를 구성한 클러스터를 의미
- 브로커 broker : 카프카 애플리케이션이 설치된 서버 또는 노드를 말함
- 프로듀서 producer : 카프카로 메시지를 보내는 역할을 하는 클라이언트를 총칭
- 컨슈머 consumer : 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트를 총칭
- 토픽 topic : 카프카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유함
- 파티션 partition : 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 말함
- 세그먼트 segment : 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일
- 메시지 message 또는 레코드 record : 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 말함
- 주키퍼 ZooKeeper : 카프카의 메타데이터 관리 및 브로커의 정상 상태 점검 health check 을 담당
- 카프카는 데이터를 받아서 전달하는 데이터 버스 data bus 의 역할
- 카프카에 데이터 (메시지) 를 만들어서 주는 쪽은 프로듀서 producer 라 부르고, 데이터를 빼내서 소비하는 쪽은 컨슈머 consumer 라 함
- 주키퍼는 카프카의 정상 동작을 보장하기 위해 메타데이터 metadata (브로커들의 노드 관리 등) 를 관리하는 코디네이터 coordinator 임
- 프로듀서와 컨슈머는 클라이언트이며, 애플리케이션은 카프카와 주키퍼임
- 카프카는 프로듀서와 컨슈머 중앙에 위치하여, 프로듀서로부터 전달 받은 메시지들을 저장하고 컨슈머에 메시지를 전달함
- 컨슈머는 카프카에 저장된 메시지를 꺼내오는 역할을 함
- 브로커 broker 는 애플리케이션이 설치된 서버 또는 노드를 의미
- 리플리케이션 replication : 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미
- 하나의 브로커가 종료되더라도 카프카는 안정성을 유지할 수 있음
- 토픽 생성 명령어 중 replication-factor 3 이면, 원본을 포함한 리플리케이션(토픽의 파티션)이 총 3개를 의미함
- 원본(토픽의 파티션)을 리더 reader, 리플리케이션을 팔로워 follower
- 리더는 프로듀서, 컨슈머로부터 오는 모든 읽기/쓰기를 처리, 팔로워는 리더로부터 복제 유지
- 파티션 partition : 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만들 것을 의미
- 나뉜 파티션의 수 만큼 컨슈머를 연결 할 수 있어서, 병렬 처리가 가능함
- 파티션 수는 초기 생성 시 언제든지 늘릴 수 있지만 늘린 파티션은 줄일 수 없음, 컨슈머 LAG 모니터링으로 판단 할 것
- 컨슈머 LAG (지연) = ‘프로듀서가 보낸 메시지 갯수(카프카에 남아 있는 메시지 갯수)’ - 컨슈머가 가져간 메시지 갯수’
- 세그먼트 segment : 토픽의 파티션에 저장된 메시지들이 세그먼트라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장됨
- 오프셋 offset : 파티션에 메시지가 저장되는 위치, 오프셋은 순차적으로 증가(0, 1, 2...)
1-1) 메시지 브로커(RabbitMQ) 와 이벤트 브로커(Kafka)차이
- 메시지 브로커
- 프로듀서가 전달한 메시지를 큐에 저장하고, 저장된 데이터를 컨슈머가 가져갈 수 있도록 해주는 브로커로 보통 서로 다른 시스템사이에서 데이터를 비동기 형태로 처리하기 위해 사용
- ex) RabbitMQ, SQS(AWS)
- 컨슈머가 큐에서 데이터를 가져가면 즉시 큐에서 데이터가 삭제되거나, 짧은 시간내에 큐에서 데이터가 삭제되는 특징이 있음
- 이벤트 브로커
- 이벤트 브로커는 기본적으로 메시지 브로커의 큐 기능을 가지고 있음
- 프로듀서가 전달한 이벤트를 처리 후에 바로 삭제하지 않고 저장하여, 컨슈머가 특정 시점부터 이벤트를 다시 컨슘(consume) 할 수 있음
- ex) 장애가 일어난 시점에서 그 이후 이벤트 재처리 가능
- ex) Kafka, Kinesis(AWS)
- 대용량 처리에 있어 메시지 브로커보다 많은 양의 데이터 처리 가능
| RabbitMQ | Kafka |
| 경량 메시지 큐 시스템으로 메시지 전송과 큐 관리에 중점 | 대규모 데이터 스트리밍 플랫폼으로 이벤트 브로커 역할도 수행 |
| 주로 메시지 큐를 통한 통신에 사용 | 대용량의 데이터 스트림을 처리하고, 분산 시스템에서의 활용이 주목받고 있음 |
2. Strimzi Operator란?
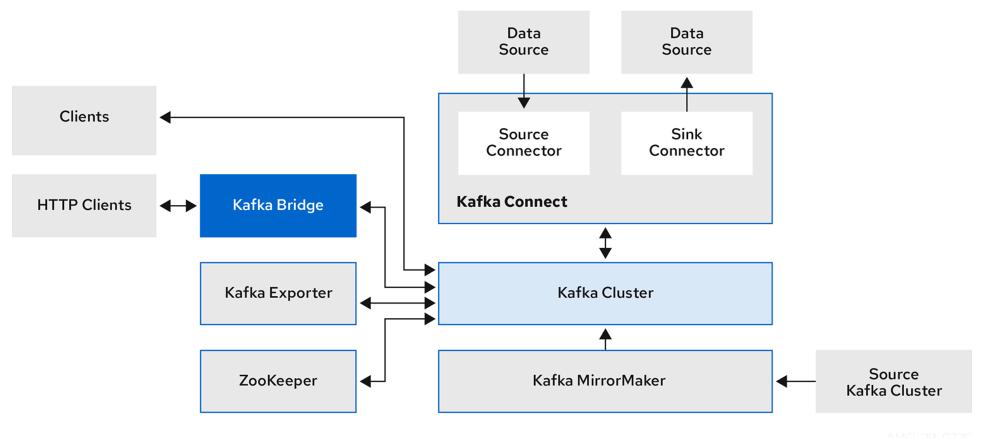
- Strimzi Operator는 Kubernetes 클러스터에서 Apache Kafka를 운영, 배포 및 관리하기 위한 오퍼레이터
- 주요 기능
- Kafka 클러스터 배포:
- Strimzi Operator는 Kafka 클러스터를 배포하기 위한 커스텀 리소스 정의(CRD)를 제공하며 이를 통해 클러스터의 크기, 구성 등을 설정가능.
- 토픽 및 파티션 관리:
- Kafka 토픽과 파티션의 생성, 확장, 축소, 삭제 등과 같은 작업
- Broker 및 Zookeeper 구성:
- Kafka 브로커 및 Zookeeper 구성과 관련된 파라미터를 변경하고 관리
- 접근 제어 및 보안:
- TLS 및 인증과 같은 보안 설정을 간편하게 구성
- 스케일링:
- Strimzi Operator는 Kafka 클러스터의 스케일링을 지원하며, 브로커 또는 파티션 수를 동적으로 조절
- Monitoring 및 Logging:
- Prometheus와 Grafana를 통한 모니터링 설정과 함께 로깅 설정을 쉽게 구성
- MirrorMaker 및 Connect 설정:
- MirrorMaker와 Kafka Connect를 설정하고 관리하여 데이터의 복제 및 외부 시스템과의 연결을 지원
- Kafka 클러스터 배포:
3. Strimzi Operator 설치 (Helm chart)
- Strimzi chart version : v0.38.0 - https://artifacthub.io/packages/helm/strimzi/strimzi-kafka-operator
# 네임스페이스 생성
kubectl create namespace kafka
# helm repo 추가
helm repo add strimzi https://strimzi.io/charts/
helm show values strimzi/strimzi-kafka-operator
# helm chart install
helm install kafka-operator strimzi/strimzi-kafka-operator \
--version 0.38.0 \
--namespace kafka
# 배포된 helm chart 리소스 확인
kubectl get deploy,pod -n kafka
kubectl get-all -n kafka
# 오퍼레이터가 지원하는 카프카 버전 확인
kubectl describe deploy -n kafka | grep KAFKA_IMAGES: -A3
STRIMZI_KAFKA_IMAGES: 3.5.0=quay.io/strimzi/kafka:0.38.0-kafka-3.5.0
3.5.1=quay.io/strimzi/kafka:0.38.0-kafka-3.5.1
3.6.0=quay.io/strimzi/kafka:0.38.0-kafka-3.6.0
# 배포한 리소스 확인 : CRDs - 각각이 제공 기능으로 봐도됨!
kubectl get crd | grep strimzi
kafkabridges.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkaconnectors.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkaconnects.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkamirrormaker2s.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkamirrormakers.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkanodepools.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkarebalances.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkas.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkatopics.kafka.strimzi.io 2023-11-17T09:24:35Z
kafkausers.kafka.strimzi.io 2023-11-17T09:24:35Z
strimzipodsets.core.strimzi.io 2023-11-17T09:24:35Z
# (참고) CRD 상세 정보 확인
kubectl describe crd kafkas.kafka.strimzi.io
kubectl describe crd kafkatopics.kafka.strimzi.io
3-1) 카프카 클러스터 생성 (Zookeeper) : 기존 Statefulsets 대신 → StrimziPodSets 이 기본 설정
- StrimziPodSets(sps) 특징 : sts 중간 파드 바로 삭제 불가, 파드 Spec 동일해야됨(볼륨, CPU, Memory), 아키텍처 구성 용이
# 새로운 터미널에 해당 명령어를 통한 모니터링 진행
watch kubectl get kafka,strimzipodsets,pod,svc,endpointslice,pvc -n kafka
kubectl logs deployment/strimzi-cluster-operator -n kafka -f
# 카프카 클러스터 YAML 파일 다운로드
curl -s -O https://raw.githubusercontent.com/gasida/DOIK/main/strimzi/kafka-1.yaml
cat kafka-1.yaml | yh
# 카프카 클러스터 배포 : 카프카(브로커 3개), 주키퍼(3개), entityOperator 디플로이먼트
## 배포 시 requiredDuringSchedulingIgnoredDuringExecution 지원 >> preferredDuringSchedulingIgnoredDuringExecution 미지원...
kubectl apply -f kafka-1.yaml -n kafka
# 배포된 리소스들 확인
kubectl get-all -n kafka
# 배포된 리소스 확인 : 주키퍼 설치 완료 후 >> 카프카 브로커 설치됨
kubectl get kafka -n kafka
kubectl get cm,secret -n kafka
# 배포된 리소스 확인 : 카프카/주키퍼 strimzipodsets 생성 확인 >> sts 스테이트풀렛 사용 X
kubectl get strimzipodsets -n kafka
# 노드 정보 확인
kubectl describe node | more
kubectl get node --label-columns=topology.ebs.csi.aws.com/zone
kubectl describe pv | grep 'Node Affinity:' -A2
# 배포된 리소스 확인 : 배포된 파드 생성 확인
kubectl get pod -n kafka -l app.kubernetes.io/name=kafka
kubectl get pod -n kafka -l app.kubernetes.io/name=zookeeper
kubectl get pod -n kafka -l app.kubernetes.io/instance=my-cluster
# 배포된 리소스 확인 : 서비스 Service(Headless) 등 생성 확인 - listeners(3개)
kubectl get svc,endpointslice -n kafka
# 배포된 리소스 확인 : 카프카/주키퍼 파드 저장소 확인
kubectl get pvc,pv -n kafka
kubectl df-pv
# 배포된 리소스 확인 : 컨피그맵 확인
kubectl get cm -n kafka
# 컨피그맵 상세 확인
kubectl describe cm -n kafka strimzi-cluster-operator
kubectl describe cm -n kafka my-cluster-zookeeper-config
kubectl describe cm -n kafka my-cluster-entity-topic-operator-config
kubectl describe cm -n kafka my-cluster-entity-user-operator-config
kubectl describe cm -n kafka my-cluster-kafka-0
kubectl describe cm -n kafka my-cluster-kafka-1
kubectl describe cm -n kafka my-cluster-kafka-2
# kafka 클러스터 Listeners 정보 확인 : 각각 9092 평문, 9093 TLS, 세번째 정보는 External 접속 시 NodePort 정보
kubectl get kafka -n kafka my-cluster -o jsonpath={.status.listeners} | jq
[
{
"addresses": [
{
"host": "my-cluster-kafka-bootstrap.kafka.svc",
"port": 9092
}
],
"bootstrapServers": "my-cluster-kafka-bootstrap.kafka.svc:9092",
"name": "plain"
},
{
"addresses": [
{
"host": "my-cluster-kafka-bootstrap.kafka.svc",
"port": 9093
}
],
"bootstrapServers": "my-cluster-kafka-bootstrap.kafka.svc:9093",
"name": "tls"
},
{
"addresses": [
{
"host": "ip-192-168-3-190.ap-northeast-2.compute.internal",
"port": 32709
},
{
"host": "ip-192-168-2-210.ap-northeast-2.compute.internal",
"port": 32709
},
{
"host": "ip-192-168-1-27.ap-northeast-2.compute.internal",
"port": 32709
}
],
"bootstrapServers": "ip-192-168-1-27.ap-northeast-2.compute.internal:32709,ip-192-168-2-210.ap-northeast-2.compute.internal:32709,ip-192-168-3-190.ap-northeast-2.compute.internal:32709",
"name": "external"
}
]
3-2) 테스트용 파드 생성 후 카프카 클러스터 정보 확인
# 파일 다운로드
curl -s -O https://raw.githubusercontent.com/gasida/DOIK/main/strimzi/myclient.yaml
cat myclient.yaml | yh
# 데몬셋으로 myclient 파드 배포 : 어떤 네임스페이스에 배포되는가?
VERSION=3.6 envsubst < myclient.yaml | kubectl apply -f -
kubectl get pod -l name=kafkaclient -owide
# Kafka client 에서 제공되는 kafka 관련 도구들 확인
kubectl exec -it ds/myclient -- ls /opt/bitnami/kafka/bin
# 카프카 파드의 SVC 도메인이름을 변수에 지정
SVCDNS=my-cluster-kafka-bootstrap.kafka.svc:9092
echo "export SVCDNS=my-cluster-kafka-bootstrap.kafka.svc:9092" >> /etc/profile
# 브로커 정보
kubectl exec -it ds/myclient -- kafka-broker-api-versions.sh --bootstrap-server $SVCDNS
# 브로커에 설정된 각종 기본값 확인 : --broker --all --describe 로 조회
kubectl exec -it ds/myclient -- kafka-configs.sh --bootstrap-server $SVCDNS --broker 1 --all --describe
kubectl exec -it ds/myclient -- kafka-configs.sh --bootstrap-server $SVCDNS --broker 2 --all --describe
kubectl exec -it ds/myclient -- kafka-configs.sh --bootstrap-server $SVCDNS --broker 0 --all --describe
# 토픽 리스트 확인
kubectl exec -it ds/myclient -- kafka-topics.sh --bootstrap-server $SVCDNS --list
# 토픽 리스트 확인 (kubectl native) : PARTITIONS, REPLICATION FACTOR
kubectl get kafkatopics -n kafka
728x90
반응형
'K8S Operator' 카테고리의 다른 글
| [K8S Operator] Vault Secrets Operator(VSO) (1) | 2023.11.26 |
|---|---|
| [K8S Operator] Percona Operator for MongoDB (1) | 2023.11.12 |
| [K8S Operator] Cloud Native PostgreSQL 오퍼레이터 (0) | 2023.11.04 |
| [K8S Operator] Operator& MySQL Operator (1) | 2023.10.29 |



